

Ați căutat vreodată ceva pe Google și v-ați întrebat „Cum știe unde să caute?” Răspunsul este „crawlerele web”, care caută pe web și îl indexează astfel încât să puteți găsi lucrurile cu ușurință online. Vă vom explica.
Motoare de căutare și crawler
Când căutați utilizând un cuvânt cheie pe un motor de căutare precum Google sau Bing, site-ul trece prin trilioane de pagini pentru a genera o listă de rezultate legate de acel termen. Cum au exact aceste motoare de căutare toate aceste pagini, știu cum să le caute și generează aceste rezultate în câteva secunde?
Răspunsul este crawlerele web, cunoscute și sub numele de păianjeni. Acestea sunt programe automate (adesea numite „roboți” sau „roboți”) care „accesează cu crawlere” sau navighează pe web, astfel încât să poată fi adăugate la motoarele de căutare. Acești roboți indexează site-urile web pentru a crea o listă de pagini care apar în cele din urmă în rezultatele căutării.
Crawlerele creează și stochează copii ale acestor pagini în baza de date a motorului, ceea ce vă permite să efectuați căutări aproape instantaneu. Este, de asemenea, motivul pentru care motoarele de căutare includ deseori versiuni cache de site-uri în bazele lor de date.
LEGATE DE: Cum să accesați o pagină web când nu mai funcționează
Hărți și selecție a site-ului
Deci, cum aleg crawlerele ce site-uri web să acceseze? Ei bine, cel mai frecvent scenariu este că proprietarii de site-uri web doresc ca motoarele de căutare să acceseze cu crawlere site-urile lor. Ei pot realiza acest lucru solicitând Google, Bing, Yahoo sau altui motor de căutare să își indexeze paginile. Acest proces variază de la motor la motor. De asemenea, motoarele de căutare selectează frecvent site-uri web populare și bine conectate pentru a le accesa cu crawlere, urmărind de câte ori o adresă URL este conectată pe alte site-uri publice.
Proprietarii de site-uri web pot utiliza anumite procese pentru a ajuta motoarele de căutare să își indexeze site-urile web, cum ar fi
încărcarea unei hărți a site-ului. Acesta este un fișier care conține toate linkurile și paginile care fac parte din site-ul dvs. web. Este utilizat în mod normal pentru a indica ce pagini doriți să fie indexate.
Odată ce motoarele de căutare au accesat cu crawlere deja un site web, vor accesa automat din nou acel site. Frecvența variază în funcție de popularitatea unui site web, printre alte valori. Prin urmare, proprietarii de site-uri păstrează frecvent hărți ale site-urilor actualizate pentru a anunța motoarele ce site-uri web noi trebuie indexate.
Roboții și factorul de politete

Ce se întâmplă dacă un site web nu doriți ca unele sau toate paginile sale să apară pe un motor de căutare? De exemplu, este posibil să nu doriți ca oamenii să caute o pagină numai pentru membri sau să vadă pagina dvs. de eroare 404. Aici intră în joc lista de excludere a accesării cu crawlere, cunoscută și sub numele de robots.txt. Acesta este un fișier text simplu care dictează crawlerelor ce pagini web să excludă de la indexare.
Un alt motiv pentru care robots.txt este important este că crawlerele web pot avea un efect semnificativ asupra performanței site-ului. Deoarece crawlerele descarcă în esență toate paginile de pe site-ul dvs. web, consumă resurse și pot provoca încetiniri. Ajung în momente imprevizibile și fără aprobare. Dacă nu aveți nevoie de paginile dvs. indexate în mod repetat, atunci oprirea crawlerelor ar putea ajuta la reducerea încărcării site-ului dvs. web. Din fericire, majoritatea crawlerelor încetează să acceseze cu crawlere anumite pagini pe baza regulilor proprietarului site-ului.
Magia metadatelor
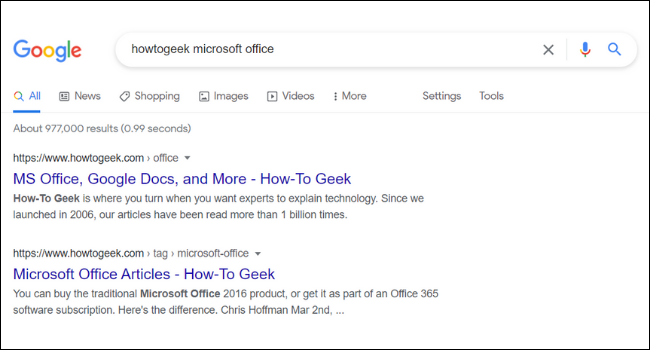
Sub adresa URL și titlul fiecărui rezultat al căutării în Google, veți găsi o scurtă descriere a paginii. Aceste descrieri se numesc fragmente. Este posibil să observați că fragmentul unei pagini din Google nu se aliniază întotdeauna la conținutul real al site-ului. Acest lucru se datorează faptului că multe site-uri web au ceva numit „metaetichete”, care sunt descrieri personalizate pe care proprietarii de site-uri le adaugă paginilor lor.
Proprietarii de site-uri vin adesea cu descrieri de metadate atrăgătoare scrise pentru a vă face să doriți să faceți clic pe un site web. Google listează, de asemenea, alte meta-informații, cum ar fi prețurile și disponibilitatea stocului. Acest lucru este util mai ales pentru cei care rulează site-uri web de comerț electronic.
Căutarea dvs.
Căutarea pe web este o parte esențială a utilizării internetului. Căutarea pe web este o modalitate excelentă de a descoperi noi site-uri web, magazine, comunități și interese. În fiecare zi, crawlerele web vizitează milioane de pagini și le adaugă la motoarele de căutare. În timp ce crawlerele au unele dezavantaje, cum ar fi utilizarea resurselor site-ului, acestea sunt de neprețuit atât pentru proprietarii site-ului, cât și pentru vizitatori.
LEGATE DE: Cum să ștergeți ultimele 15 minute din Istoricul căutărilor Google


